HyperText Markup Language, or HTML, is the primary language for web pages on the internet. It includes support for a number of other languages that add extra functionality and styling such as JavaScript and CSS. All of these languages are text-based with some meaningful characters used to separate literal strings that should be printed to the browser and code that should be interpreted and executed.
This design has some issues though, these become obvious when you want to print one of the meaningful characters to the browser. The best example characters to use are the “less than” and “greater than” symbols. Respectively these symbols are used to open and close code segments in HTML. The correct method of printing these characters to the screen safely is to use HTML entities.
HTML entities and security
Thanks to these characters having a special meaning you have to be really careful to make sure that you replace them with the HTML entity version if you want them to be printed to the browser. Unfortunately, many web developers forget that users can submit input to many websites. If this user input includes meaningful characters and they aren’t replaced with HTML entities, in a process called sanitisation, then the website has a Cross-Site Scripting (XSS) vulnerability.
Tip: Don’t try submitting special characters to websites in an attempt to find XSS vulnerabilities. Doing so is technically hacking and is a criminal offence unless you have permission from the owner of the website.
How HTML entities work (and sometimes don’t)
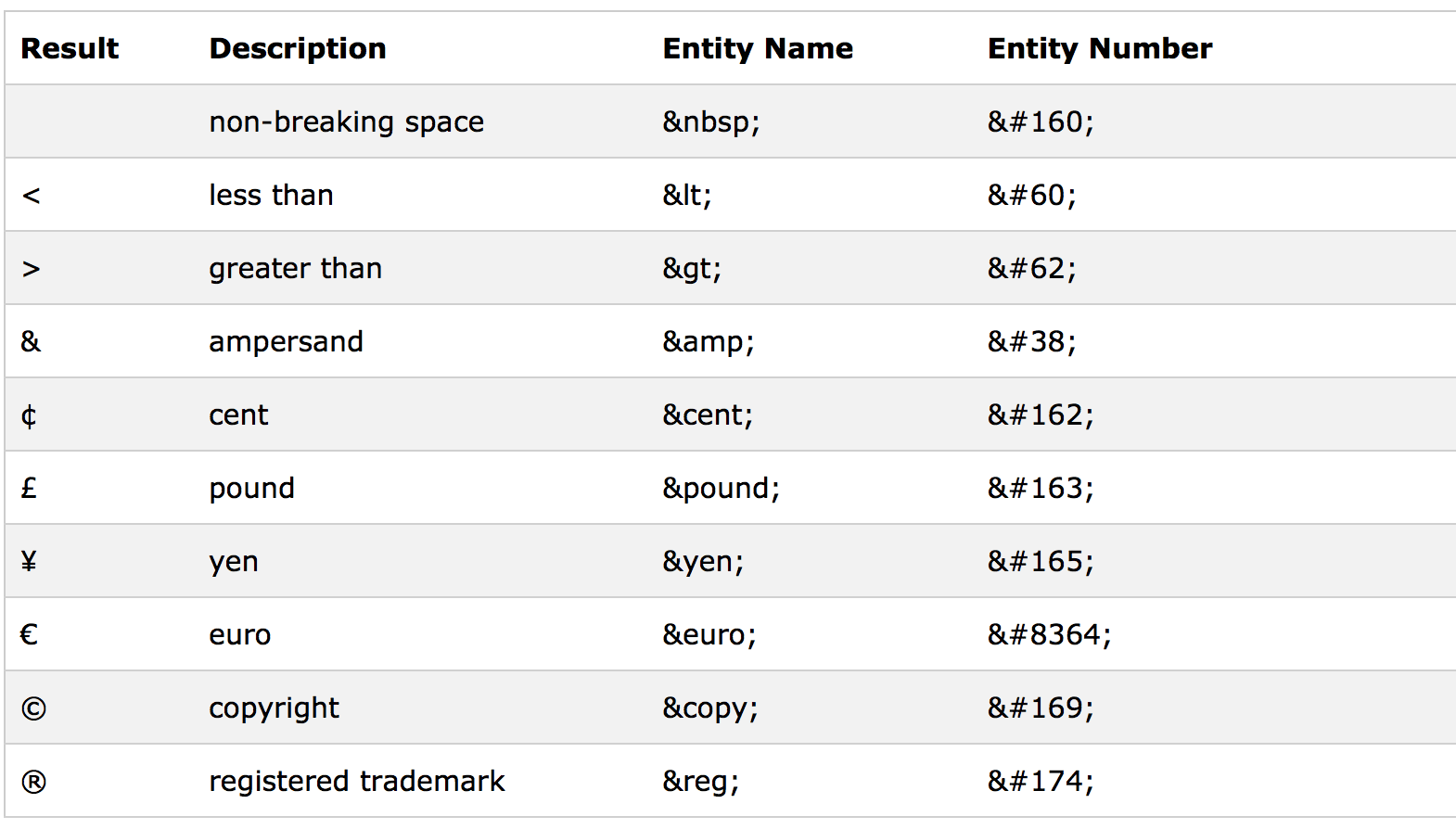
HTML entities work because the browser knows to display it as the relevant special character and to not treat it as a special character. All HTML entities start with an ampersand “&” and end with a semi-colon “;”. Most characters are identified by an entity number although some special characters have a shorthand name too. For example “&”, “<”, and “>” have the entity numbers “&”, “<”, and “>” as well as the entity names “&”, “<”, and “>” respectively. The browser knows that these strings mean it needs to display the relevant characters.
Tip: A full list of character entity names can be found here, although entity name support varies by browser.
In most cases, users should only ever see the characters that HTML entities represent. It’s possible, however, to see encoded characters, commonly ampersand “&”, through a process called “Double encoding”. This happens as the ampersand character appears in its own encoded version. Double encoding generally happens when input is correctly encoded, as it’s submitted, however, when it’s being output it gets sanitised again. This results in the ampersand at the start of the “&” getting encoded a second time and appearing as “&amp;”, the browser then correctly interprets that as a string that should be printed as “&” having decoded the HTML entity and ignored the partial entity.